Installing Hadoop 3.2.1 on Windows
1.Prerequisites
First, we need to make sure that the following prerequisites are installed:
- Java 8 runtime environment (JRE): Hadoop 3 requires a Java 8 installation. I prefer using the offline installer.
- Java 8 development Kit (JDK)
- To unzip downloaded Hadoop binaries, we should install 7zip
- I will create a folder on my local machine to store downloaded Hadoop files "Drive_Name:\Hadoop_evn"
2. Download Hadoop Barriers
The first step is to download Hadoop binaries from the official website. The binary package size is about 342 MB.
or
Better to download Hadoop Binaries from the nonofficial. you can directly utilize these file.
After finishing the file download, we should unpack the package using 7zip int two steps. First, we should extract the hadoop-3.2.1.tar.gz library, and then, we should unpack the extracted tar file
3. Setting up environmental Variables
After installing Hadoop and its prerequisites, we should configure the environment variables to define Hadoop and Java default paths.
To edit environment variables,
go to Control Panel >
System and Security >
System (or right-click > properties on My Computer icon) and
click on the “Advanced system settings” link.
When the “Advanced system settings” dialog appears,
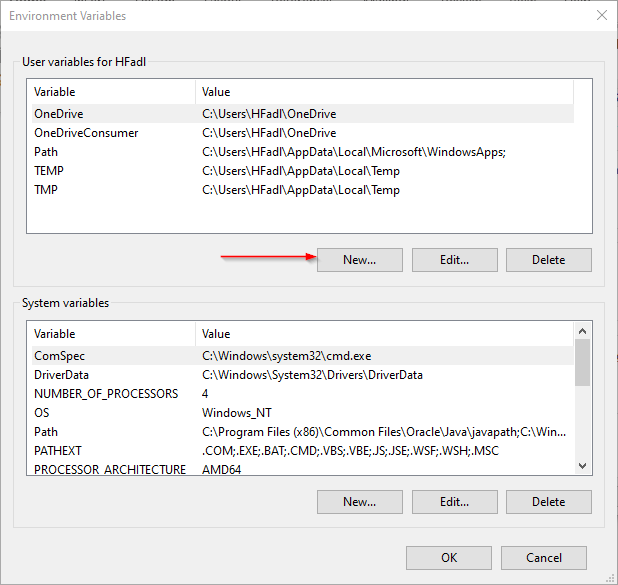
go to the “Advanced” tab and click on the “Environment variables” button located on the bottom of the dialog.
In the “Environment Variables” dialog, press the “New” button to add a new variable.
There are two variables to define:
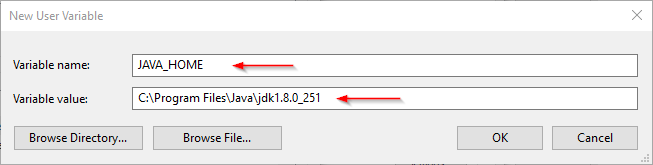
- JAVA_HOME: JDK installation folder path
- HADOOP_HOME: Hadoop installation folder path
 |
| Adding JAVA_HOME Variable |
 |
| Adding JAVA_HOME PATH |
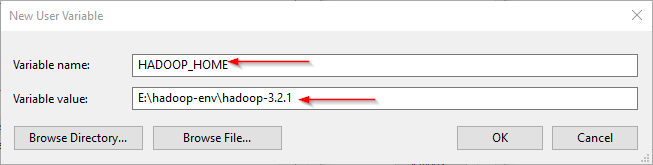 |
| Adding HADOOP_HOME PATH |
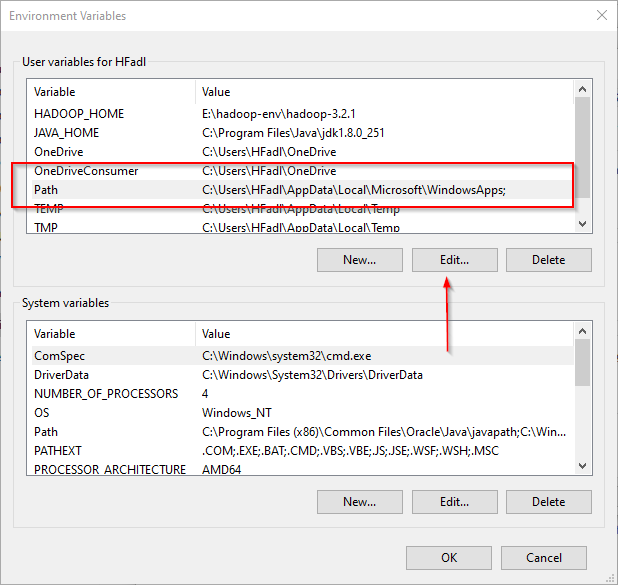 |
| Editing Path Variables |
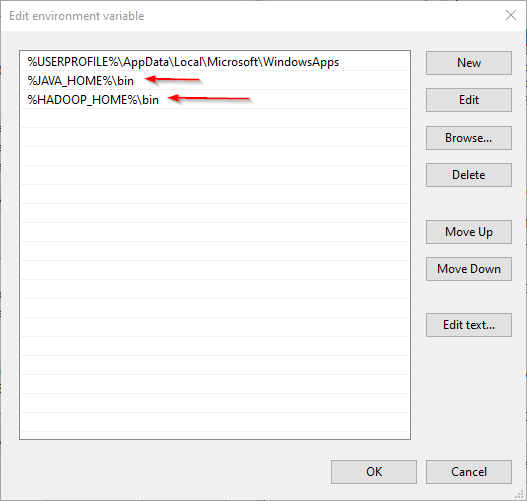 |
| Adding New Path to the PATH Variables |
3.1 JAVA Incorrectly set error
Now, let’s open PowerShell and try to run the following command:
hadoop -version
In this example, since the JAVA_HOME path contains spaces, I received the following error:
JAVA_HOME is incorrectly set
 |
| JAVA_HOME Error |
To solve this issue, we should use the windows 8.3 path instead. As an example:
Use “Progra~1” instead of “Program Files”
Use “Progra~2” instead of “Program Files(x86)”
After replacing “Program Files” with “Progra~1”, we closed and reopened PowerShell and tried the same command. As shown in the screenshot below, it runs without errors.
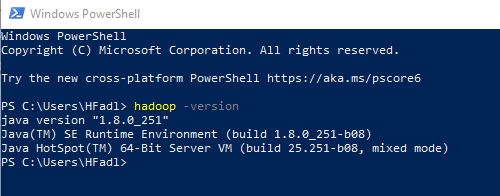 |
| Hadoop version command executed successfully |
4. Configuring Hadoop Cluster
There are four files we should alter to configure Hadoop cluster:
%HADOOP_HOME%\etc\hadoop\hdfs-site.xml
%HADOOP_HOME%\etc\hadoop\core-site.xml
%HADOOP_HOME%\etc\hadoop\mapred-site.xml
%HADOOP_HOME%\etc\hadoop\yarn-site.xml
4.1. HDFS site configuration
As we know, Hadoop is built using a master-slave paradigm. Before altering the HDFS configuration file, we should create a directory to store all master node (name node) data and another one to store data (data node). In this example, we created the following directories:
E:\hadoop-env\hadoop-3.2.1\data\dfs\namenode
E:\hadoop-env\hadoop-3.2.1\data\dfs\datanode
Now, let’s open “hdfs-site.xml” file located in “%HADOOP_HOME%\etc\hadoop” directory, and we should add the following properties within the <configuration></configuration> element:
Note: Give You Drive Name Properly in the place of file path.
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:///Your Drive Name( C/D/E/etc):/hadoop-env/hadoop-3.2.1/data/dfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:///Your Drive Name( C/D/E/etc):/hadoop-env/hadoop-3.2.1/data/dfs/datanode</value></property>
Note that we have set the replication factor to 1 since we are creating a single node cluster.
4.2. Core site configuration
Now, we should configure the name node URL adding the following XML code into the <configuration></configuration> element within “core-site.xml”:
<property><name>fs.default.name</name><value>hdfs://localhost:9820</value></property>
4.3. Map Reduce site configuration
Now, we should add the following XML code into the <configuration></configuration> element within “mapred-site.xml”:
<property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce framework name</description></property>
4.4. Yarn site configuration
Now, we should add the following XML code into the <configuration></configuration> element within “yarn-site.xml”:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>Yarn Node Manager Aux Service</description></property>
5. Formatting Name node
After finishing the configuration, let’s try to format the name node using the following command:
hdfs namenode -format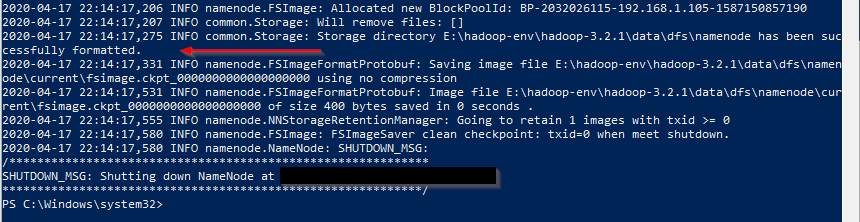
6. Start Hadoop Services
Now, we will open PowerShell, and navigate to “%HADOOP_HOME%\sbin” directory. Then we will run the following command to start the Hadoop nodes:
.\start-dfs.cmd
Comments